Apache Storm jest projektem open source i służy do przetwarzania strumieniowego w czasie rzeczywistym. Ułatwia wykonywanie działań na nieograniczonych strumieniach danych. Może być używany z dowolnym językiem programowania. Przed samym rozpoczęciem zabawy z Apache Storm przygotowałam trochę teorii, która ułatwi nam późniejszą pracę z tym projektem.
W Apache Storm wykorzystywany jest model pojedynczego przetwarzania strumieniowego, który reprezentowany jest za pomocą grafu obliczeniowego zwanego topologią (ang.topology). Polega on na przekształcaniu strumieni w nowe strumienie przy jednoczesnym aktualizowaniu bazy danych. W modelu tym za pomocą jednego pliku wdrożonego do klastra jesteśmy w stanie wykonywać różne operacje na różnych węzłach (np. filtrowanie danych w jednym węźle, agregacja w drugim). Nie musimy pisać osobnych programów dla każdego węzła. Składowe modelu:
- krotki (ang.tuples)
- strumienie (ang.streams)
- wylewki (ang.spouts)
- gromy (ang.bolts)
Krotka jest ciągiem wartości (danych). Strumień jest rdzeniem modelu składającym się z nieskończonej sekwencji krotek.  Wylewka jest źródłem strumieni. Odczytuje ona dane i przekształca je w strumienie krotek.
Wylewka jest źródłem strumieni. Odczytuje ona dane i przekształca je w strumienie krotek. 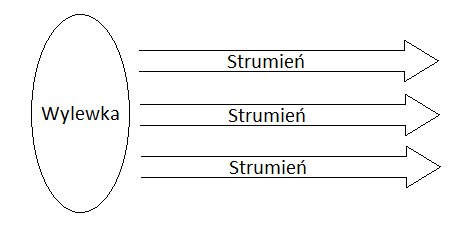 Grom wykonuje określone funkcje na strumieniach (np. złączenia, agregacje). Na wejściu dostaje przynajmniej jeden strumień wejściowy i generuje dowolną ilość strumieni wyjściowych.
Grom wykonuje określone funkcje na strumieniach (np. złączenia, agregacje). Na wejściu dostaje przynajmniej jeden strumień wejściowy i generuje dowolną ilość strumieni wyjściowych. 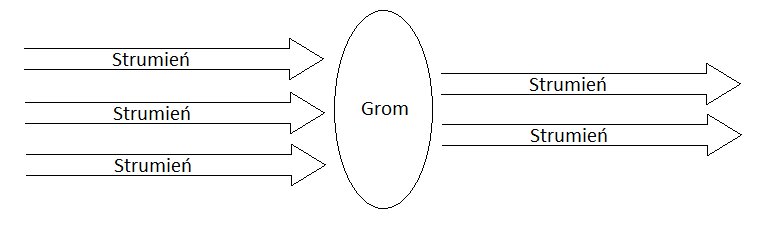 Po zdefiniowaniu wszystkich składowych powstaje topologia, która łączy wylewki i gromy oraz określa przepływ krotek przez aplikację. Zadanie (ang.task) to instancja gromu lub wylewki. W modelu tym wykonywane są one równolegle. Ponieważ zadania wykonywane są równolegle ważne jest określenie, które zadanie otrzyma daną krotkę. W tym celu wykorzystuje się grupowanie strumieni (ang. stream grouping). Najprostszym przykładem jest grupowanie tasujące (ang.shuffle grouping). Wykorzystuje ono losowy algorytm round-robin, aby równomiernie rozdzielić krotki na poszczególne zadania. W następnych wpisach znajdziecie praktyczne zastosowanie przedstawionej teorii z wykorzystaniem Apache Storm.
Po zdefiniowaniu wszystkich składowych powstaje topologia, która łączy wylewki i gromy oraz określa przepływ krotek przez aplikację. Zadanie (ang.task) to instancja gromu lub wylewki. W modelu tym wykonywane są one równolegle. Ponieważ zadania wykonywane są równolegle ważne jest określenie, które zadanie otrzyma daną krotkę. W tym celu wykorzystuje się grupowanie strumieni (ang. stream grouping). Najprostszym przykładem jest grupowanie tasujące (ang.shuffle grouping). Wykorzystuje ono losowy algorytm round-robin, aby równomiernie rozdzielić krotki na poszczególne zadania. W następnych wpisach znajdziecie praktyczne zastosowanie przedstawionej teorii z wykorzystaniem Apache Storm.