![]()
Zgodnie z wcześniejszymi zapowiedziami pokaże wam dziś jak stworzyć podpowiadanie wyszukiwanych fraz podobnie jak działa to w wyszukiwarce Google. Wykorzystam do tego mechanizmy Facety, które są elementem Apache Solr’a i z których można z powodzeniem korzystać w Spring Boot’cie.
Dla wszystkich, którzy dalej mają wątpliwości krótki GIF jak działa autocomplete:
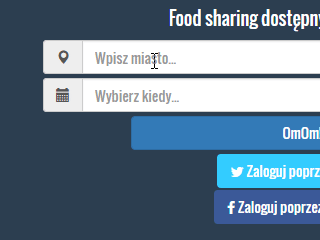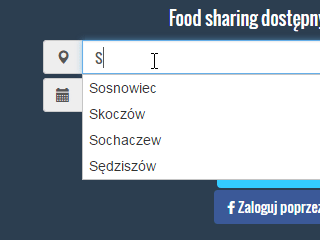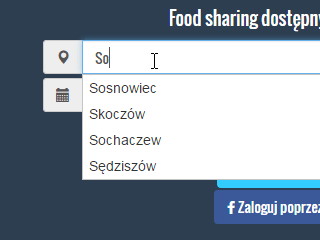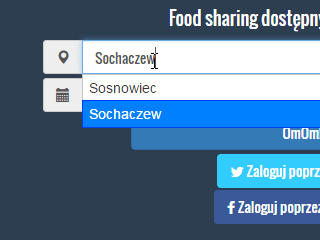
W tym wpisie będę korzystał z już wcześniej zaimportowanych danych w Apache Solr. Dlatego też odsyłam do poprzednich wpisów jeśli nie masz jeszcze danych na serwerze:
- http://codecouple.pl/2016/12/09/apache-solr-wyszukiwanie-pelnotekstowe/ – instalacja oraz wstęp,
- http://codecouple.pl/2016/12/30/apache-solr-dih-database-import-handler-mysql/ – import danych z MySQL(nieobowiązkowe).
Jeśli wykonaliśmy kroki z poprzednich wpisów powinniśmy mieć wypełnioną bazę danymi. Nie zaczniemy pracy bez odpowiednich zależności:
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-solr</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-thymeleaf</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
<dependency>
<groupId>org.webjars</groupId>
<artifactId>bootstrap</artifactId>
<version>3.3.5</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
- spring-boot-starter-data-solr – pakiet z funkcjonalnością Solr’a,
- spring-boot-starter-thymeleaf – dla UI (opcjonalnie),
- lombok – niewymagany, ja korzystam, aby uniknąć zbędnego boilerplatu (opcjonalnie),
- boostrap – dla UI (opcjonalnie),
- spring-boot-starter-web – potrzebny do wystawiania endpointów,
- spring-boot-starter-test – dla testów (opcjonalnie)
Kolejnym krokiem do wykonania jest zamodelowanie naszego obiektu:
@Data
@NoArgsConstructor
@AllArgsConstructor
@SolrDocument(solrCoreName = "products")
public class Product {
@Id
@Field
private String id;
@Field(value = "product_name")
private String productName;
public Product(String productName) {
this.productName = productName;
}
}
Adnotacje @Data, @NoArgsConstructor, @AllArgsConstructor są to elementy Lomboka, który generuje za nas między innymi gettery i settery, konstruktory oraz inne podstawowe elementy klasy. Dzięki temu nie mamy zbędnego boilerplatu. Kolejną adnotacją jest @SolrDocument, jest to już adnotacja z pakietu spring-boot-starter-data-solr. Defniujemy w niej solrCoreName co oznacza nazwę Core, w którym przechowujemy nasze dane. Nazwa ta została ustawiona podczas tworzenia nowego Core (tworzenie Core opisywałem w poprzednim wpisie). @Id oznacza, iż to pole w klasie będzie unikalnym identyfikatorem dla instancji tej klasy.
@Field jest kolejną adnotacją z pakietu Solr’a. Wszystkie pola oznaczone tą adnotacją zostaną zapisane w bazie. Nazwa w bazie będzie taka sama jak nazwa pola, możemy to zmienić poprzez użycie @Field(value = "my_name").
Możemy także ustawić czy chcemy, aby nasze pole nie było persystowane @Indexed(readonly = true) lub czy chcemy, aby nasze pole było polem dynamicznym @Dynamic.
Gdy zamodelowaliśmy nasz obiekt domenowy należy go teraz w jakiś sposób zapisać w bazie. Użyjemy do tego abstrakcji dostarczanej przez Spring Boot’a, wykorzystujemy interfejs repozytorium. Stwórzmy nasz interfejs, który będzie rozszerzał SolrCrudRepository<T, ID>.
@Repository
public interface ProductRepository extends SolrCrudRepository<Product, String> {
@Facet(fields = { "product_name" })
FacetPage<Product> findByProductNameIgnoreCaseStartingWith(String productName, Pageable pageable);
}
Nasze zapytanie tworzymy korzystając z abstrakcji Spring Data. Adnotacja @Facet służy nam do wywołania opcji Facet na naszym Core. Możemy także dodać adnotacje @Query i sami zdefiniować zapytanie. Ja natomiast korzystam z dobrodziejstw Spring Data.
Teraz stwórzmy sobie serwis, który będzie warstwą komunikacji z usługami. Stwórzmy interfejs ProductService, a potem jego implementację ProductServiceImpl.
public interface ProductService {
FacetPage<Product> autocomplete(String query, Pageable pageable);
void addProduct(String productName);
}
Implementacja serwisu:
@Service
public class ProductServiceImpl implements ProductService {
private final ProductRepository productRepository;
@Autowired
public ProductServiceImpl(ProductRepository productRepository) {
this.productRepository = productRepository;
}
@Override
public FacetPage<Product> autocomplete(String query, Pageable pageable) {
if(StringUtils.isBlank(query)) {
return new SolrResultPage<>(Collections.emptyList());
}
return productRepository.findByProductNameIgnoreCaseStartingWith(query, pageable);
}
@Override
public void addProduct(String productName) {
productRepository.save(new Product(productName));
}
}
Mamy model, mamy repozytorium i serwis, pora na kontroler:
@Slf4j
@Controller
public class ProductController {
private final ProductService productService;
@Autowired
public ProductController(ProductService productService) {
this.productService = productService;
}
@RequestMapping(value = "/autocomplete", produces = "application/json")
public @ResponseBody
Set<String> autoComplete(@RequestParam("term") String query,
@PageableDefault(page = 0, size = 1) Pageable pageable) {
if (!StringUtils.hasText(query)) {
return Collections.emptySet();
}
FacetPage<Product> result = productService.autocomplete(query, pageable);
Set<String> titles = new LinkedHashSet<>();
for (Page<FacetFieldEntry> page : result.getFacetResultPages()) {
for (FacetFieldEntry entry : page) {
Optional<String> entryValue = Optional.ofNullable(entry.getValue());
if(entryValue.isPresent() && entryValue.get().contains(query.toLowerCase())){
titles.add(StringUtils.capitalize(entryValue.get()));
}
}
}
return titles;
}
@GetMapping("/")
public String showSearchPage(){
return "index";
}
}
Teraz wystarczy dodać w klasie uruchamiającej przykładowe dane (jeśli nie robiliśmy tego wcześniej):
@SpringBootApplication
public class SolrAutocomplete implements CommandLineRunner{
@Autowired
private ProductService productService;
public static void main(String[] args) {
SpringApplication.run(SolrAutocomplete.class, args);
}
@Override
public void run(String... strings) throws Exception {
productService.addProduct("Code");
productService.addProduct("Couple");
productService.addProduct(".pl");
}
}
Ostatni punkt to dodanie widoku. Tworzymy plik index.html (jeśli korzystamy z Thymelaf’a dodajemy go do resources/templates). I wstawiamy nasz input do wpisywania:
... <input type="text" id="product_name" class="form-control" placeholder="Product name here..."/> ...
W pliku ze skryptami dodajemy autocomplete (aby działała nam funkcja autocomplete musimy dodać jquery-iu, oraz jquery do sekcji head):
$(function() {
$("#product_name")
.autocomplete(
{
source : 'http://localhost:8083/autocomplete',
minLength : 1,
});
});
Teraz, gdy udamy się pod nasz endpoint "/" pokaże się nam pole do wpisywania. Spróbujcie wpisać “C“, w podpowiedziach pokażą się słowa “Code” i “Couple“. Całość znajdziecie na GitHub’ie.
W następnym wpisie kolejne funkcje Apache Solr’a!